Lucene词典和FST
一、Lucene词典和词典索引
为了解释Lucene的词典,我们可以回忆一下新华字典的索引,如下图:
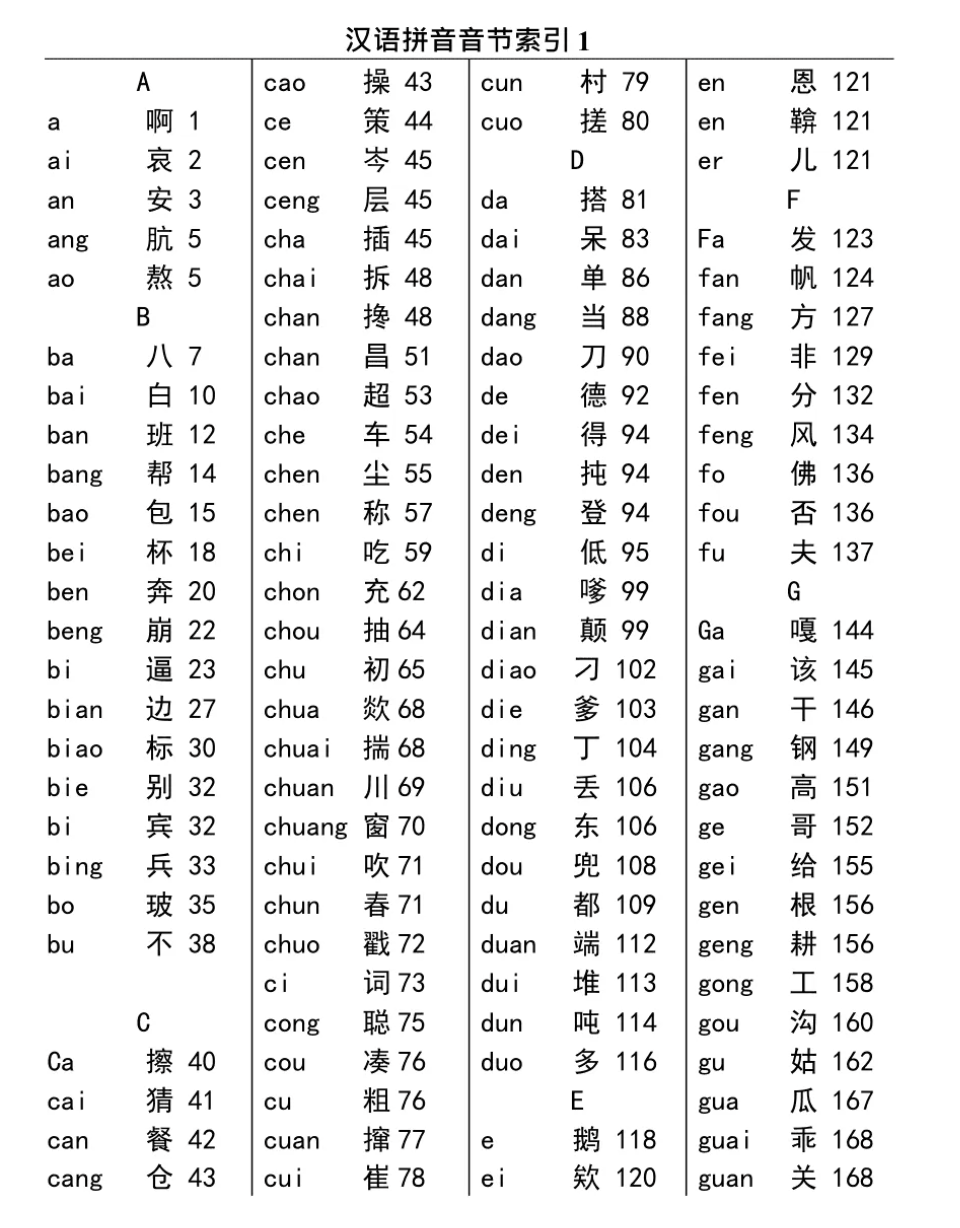 从这张图我们可以看到,字典索引的结构包含的几个信息:
从这张图我们可以看到,字典索引的结构包含的几个信息:
- 按照拼音首字母分块
- 按照拼音排序
- 存了拼音、汉字和页码的映射关系
这几个特性也在我们的Lucene中体现,Lucene的词典和词典索引主要
存储在后缀.tim和.tip文件,词典对于Lucene来说至关重要,为理解Lucene的词典,我们可以看一张抽象图。
我们有两个文档,分别有两个域,id和content :
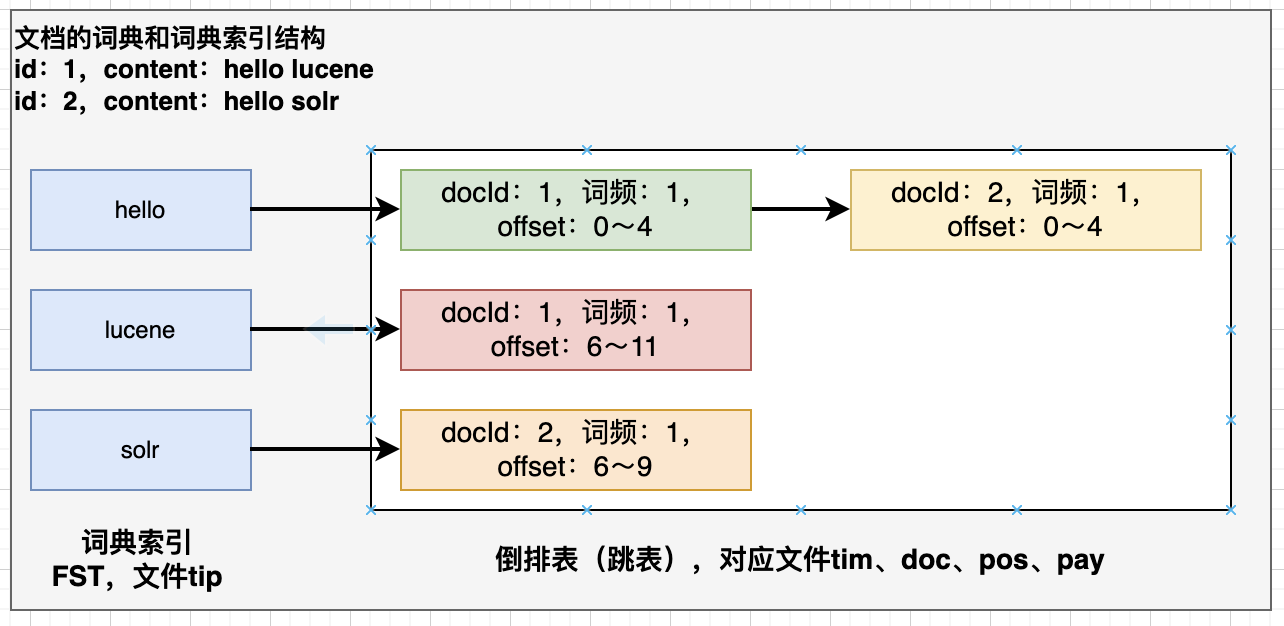 我们的索引抽象图大概就是这样,索引数据主要存储在tip、tim、doc、pos、pay这几个后缀的文件格式里。
从上图也可以看出,这个词典的结构其实就是一个KV数据结构,我们通过term可以快速找到term meta信息,如何实现词典结构呢,我们可以对比一下几种数据结构:
我们的索引抽象图大概就是这样,索引数据主要存储在tip、tim、doc、pos、pay这几个后缀的文件格式里。
从上图也可以看出,这个词典的结构其实就是一个KV数据结构,我们通过term可以快速找到term meta信息,如何实现词典结构呢,我们可以对比一下几种数据结构:
- HashMap
作为最典型的KV存储数据结构,我们肯定第一时间想到的是HashMap,但是Lucene没有选择HashMap,HashMap虽然查找性能好,但是内存占用大,还需存储额外的hash值,对于动则几千万上亿的搜索引擎是不可能采用这样的数据结构的,而且HashMap也无法进行模糊查询。
- Skip List
跳跃表事实上曾经做为Lucene的词典索引结构使用,但是在Lucene 4之后被FST替换,跳跃表性能优秀,存储也比HashMap占用少,也可以支持前缀搜索,但是无奈FST更加优秀
- Tire 前缀树
前缀树数据结构是一种典型的字典树结构,可以节省部分内存,但是无法共用后缀,数据结构示意图前缀树
- FST
有限状态转换机,Lucene 4后大量的使用在各种词典结构中,通过共用前缀、后缀等,将数据大量压缩,大大减少了内存的消耗,性能虽然比不上HashMap,但是减少大量的内存消耗,FST与其说是一种数据结构,不如说是一种压缩算法。
二、FST介绍
前面我们用介绍了Lucene的词典,就是为了FST做铺垫。
2.1 FSM 和 FSA
为了帮助理解FST我们先介绍,FSM(有限状态机)和FSA(有限状态接受机)
-
FSM 有限状态机表示有限个状态(State)集合以及这些状态之间转移和动作的数学模型。其中一个状态被标记为开始状态,0个或更多的状态被标记为final状态。 一个FSM同一时间只处于1个状态,我们以吃饭睡觉打豆豆来说明这个模型
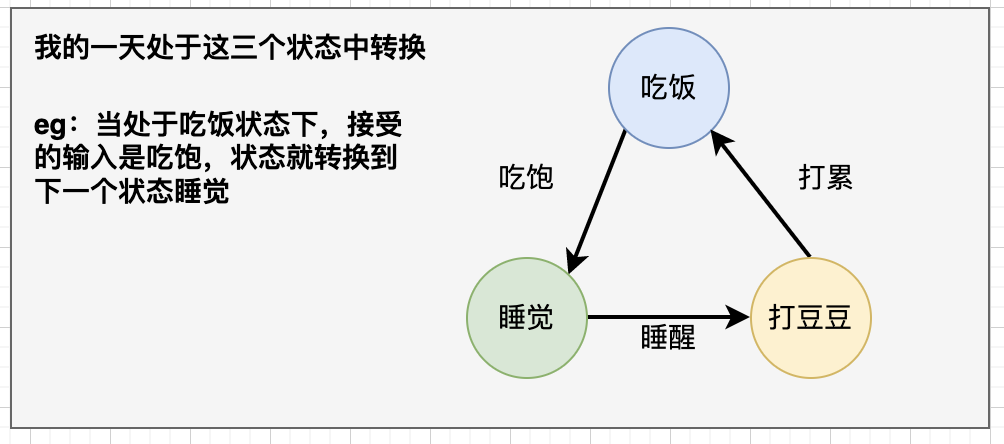 如果我们处于吃饭状态依次进行输入: 吃饱、谁醒、打累
我们就得到一个明确的状态变化过程:睡觉-> 打豆豆 -> 吃饭。
如果我们处于吃饭状态依次进行输入: 吃饱、谁醒、打累
我们就得到一个明确的状态变化过程:睡觉-> 打豆豆 -> 吃饭。 -
FSA FSA是一个FSM(有限状态机)的一种,特性如下:
- 确定:意味着指定任何一个状态,只可能最多有一个转移可以访问到。
- 无环: 不可能重复遍历同一个状态
- 接收机:有限状态机只“接受”特定的输入序列,并终止于final状态
我们可以看看其抽象的数学模型的示例,我们有几组特定的输入:abs、cos、cut,从初始状态node 0 到终止状态node 5,我们仅接受这三种有效的输入序列
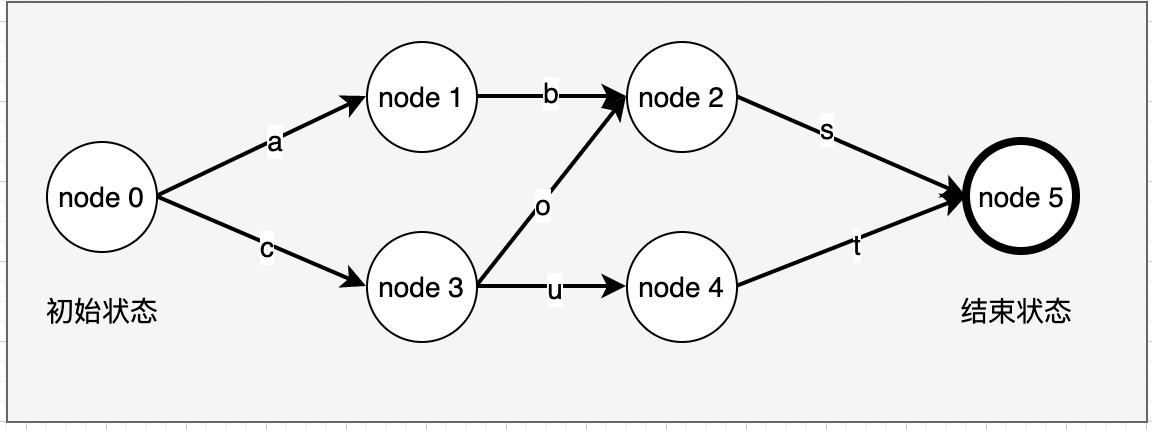
2.2 FST
基于对FSM和FSA的理解,我们来看看FST的定义: FST是也一个有限状态机(FSM),具有这样的特性:
- 确定:意味着指定任何一个状态,只可能最多有一个转移可以遍历到。
- 无环: 不可能重复遍历同一个状态
- transducer:接收特定的序列,终止于final状态,同时会输出一个值
可以看到在FSA的基础上加上outputValue就是FST了。 FST有6个元素:
- 有限的状态集
- 有限的输入符号集
- 有限的输出符号集
- 初始状态
- 终止状态集
- 转换函数
如果我们将上面FSA的三个输入序列abs、cos、cut,增加上输出值,那么FST就可以表示KV数据了,这下和我们的词典索引就开始有点像了。例如:abs/1、cos/8、cut/15,如果按照FST的6个元素来解释就是:
- 有限状态集{node 0,node 1,node 2,node 3,node 4,node 5}
- 有限输入集{"abs","cos","cut"}
- 有限输出集{1,8,15}
- 初始状态 node 0
- 终止状态集{node 5}
如果用图示来表示就是:
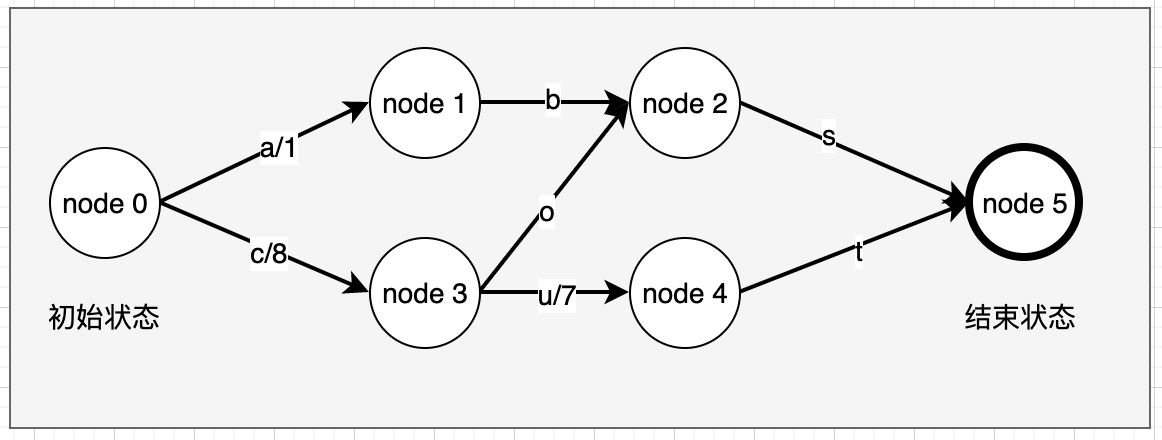 我们可以看到状态转换的弧上面已经有输出值了,如果我们遍历cut这个序列,并获的其输出值,沿着node 0 -> node 3 -> node 4 -> node 5遍历,匹配其输入序列cut,并获得其输出值8+7=15
我们可以看到状态转换的弧上面已经有输出值了,如果我们遍历cut这个序列,并获的其输出值,沿着node 0 -> node 3 -> node 4 -> node 5遍历,匹配其输入序列cut,并获得其输出值8+7=15
2.2.1 FST的构建
看到这里大家应该都清楚了FST的数据表示模型,接下来我们可以来看看FST的构建过程,为了凸显FST的构建过程和FST的压缩能力,我们采用重复率较高的一些输入term来表示,我们使用abc/4、abs/7、absef/15、solr/45、sonar/66 来演示FST有向无环图的构建过程,说明一下,我们的输入序列要求必须是排序过的,这一点我们在构建的过程中就会明白。为了快捷作图,我们使用FST Demo
-
添加abc/4 可以看到我们构建了4个状态,3条弧即是我们的输入序列,输入值为4,赋值给了第一条弧(后面我们会理解为什么是这样赋值的)

-
添加abs/7 第3状态和第四状态增加一条弧s/3,这里就明白了为啥要赋值给a/4,这样后续添加时调整输出值是最小的。

-
添加absef/15 注意这里这个图有问题,s/3对应的这个节点是一个终止状态节点

-
添加solr/45 这时可以将b/0,c/0, s/3, e/8, f/0 都冻结起来

-
添加sonar/66 完成FST的构建,将剩余的弧的数据全部写入字节数组中

全部的FST的构建就完成了,我们可以看到仅用12条弧(12个int,5个long,当然还有其他辅助信息)就可以完成5对字符串KV的存储,而正式的词典中,会有大量的重复字符,压缩比例会更大,后面我们会在Lucene中解释如何将这个图存储下来。
2.2.2 FST的查询
FST的查询会比较容易理解,我们沿着初始状态按照输入的序列进行遍历,当遍历到终止状态时即可以获得其输出值。 例如:我们输入solr序列,遍历的输出值是:45+0+0+0=45
三、Lucene中的词典索引FST
前面两节,我们已经了解了Lucene词典索引和FST的抽象存储结构,下面我们来结合代码,弄清楚Lucene词典索引、Lucene词典、FST、Skiplist的相关数据结构。
3.1 doc、pos、pay、tim、tip文件
索引文件的解释摘抄自:doc、pos、pay文件 tim、tip文件 感谢大师的分享
-
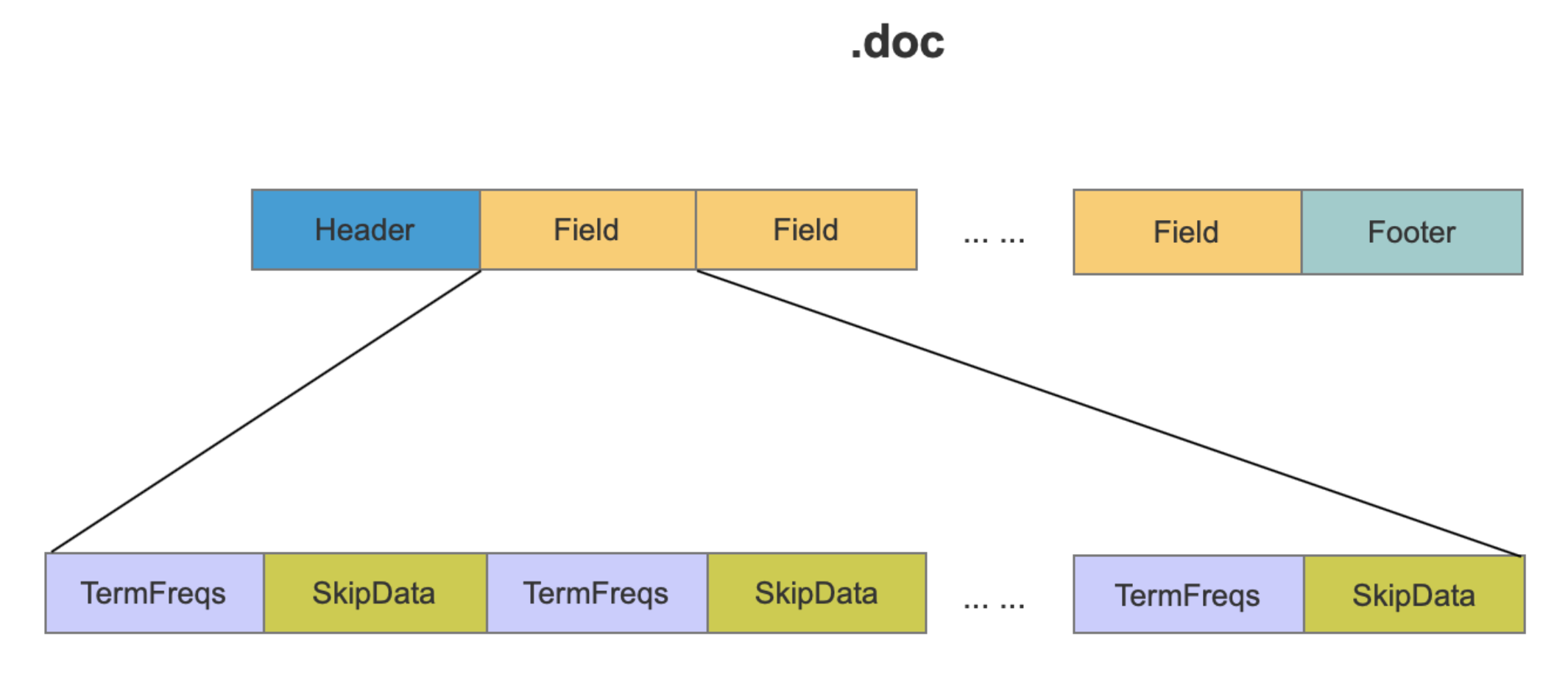
doc文件 TermFreqs保存了term的所有文档号、词频信息,TermFreqs中按块存储,使用SkipData实现这些块之间的快速跳转
-
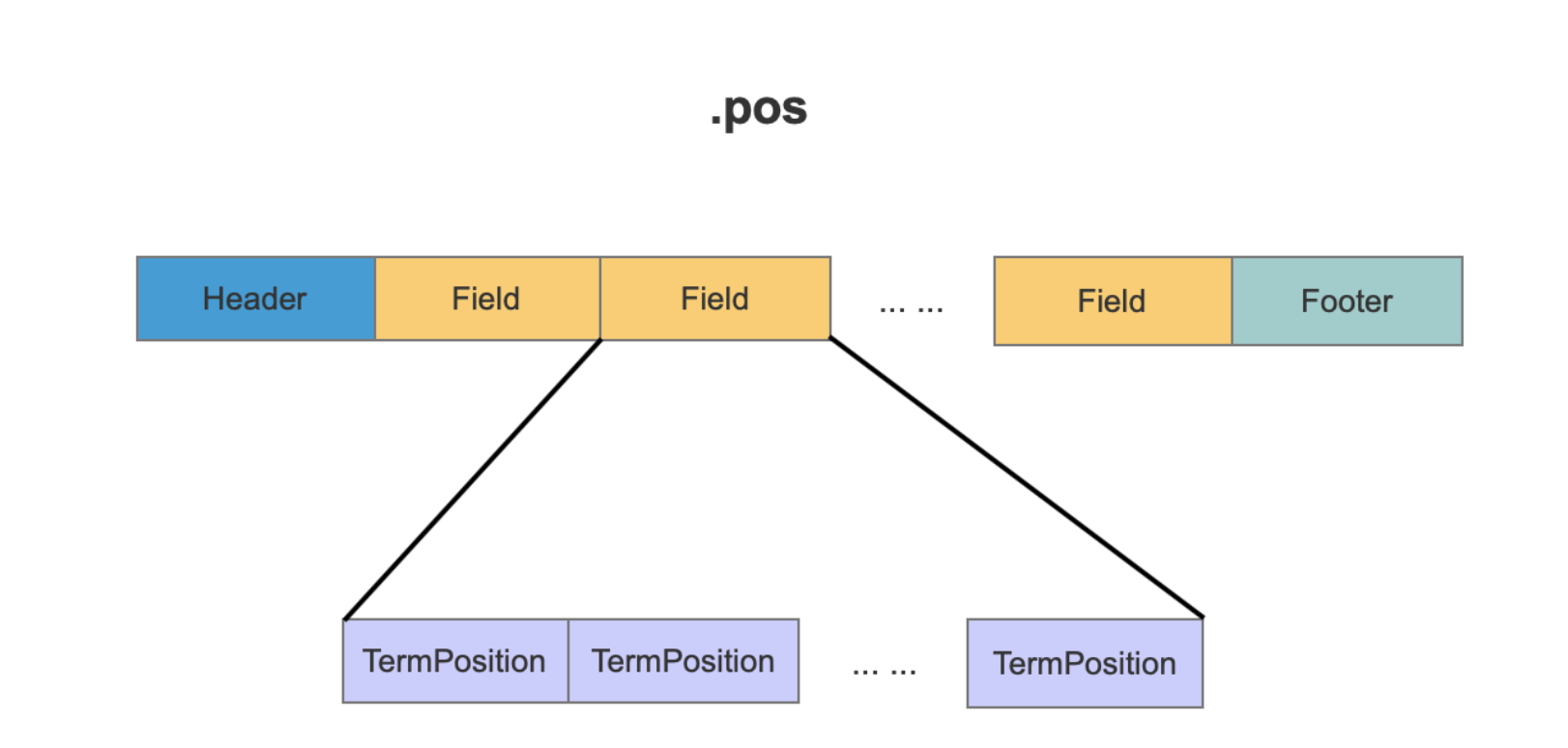
pos文件 position在Lucene中描述的是一个term在一篇文档中的位置,并且存在一个或多个position,TermPosition记录一个term的position信息
-
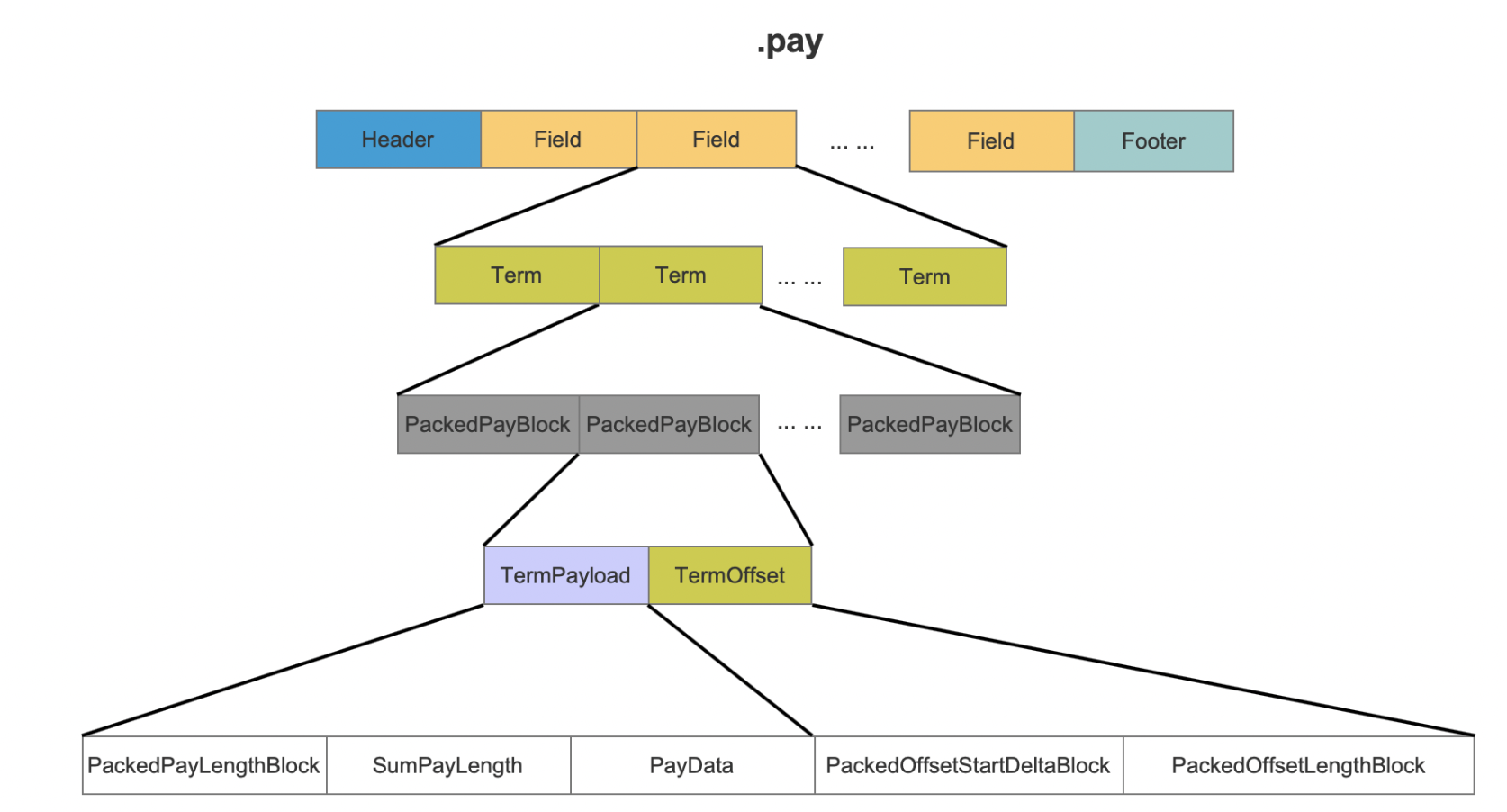
pay文件 pay文件用来存储term的payload和offset的信息
-
tim文件 .tim(TermDictionary)文件中存放了每一个term的TermStats,TermStats记录了包含该term的文档数量,term在这些文档中的词频总和;另外还存放了term的TermMetadata,TermMetadata记录了该term在.doc、.pos、.pay文件中的信息,这些信息即term在这些文件中的起始位置,即保存了指向这些文档的索引;还存放了term的Suffix,对于有部分相同前缀值的term,只需存放这些term不相同的后缀值,即Suffix。
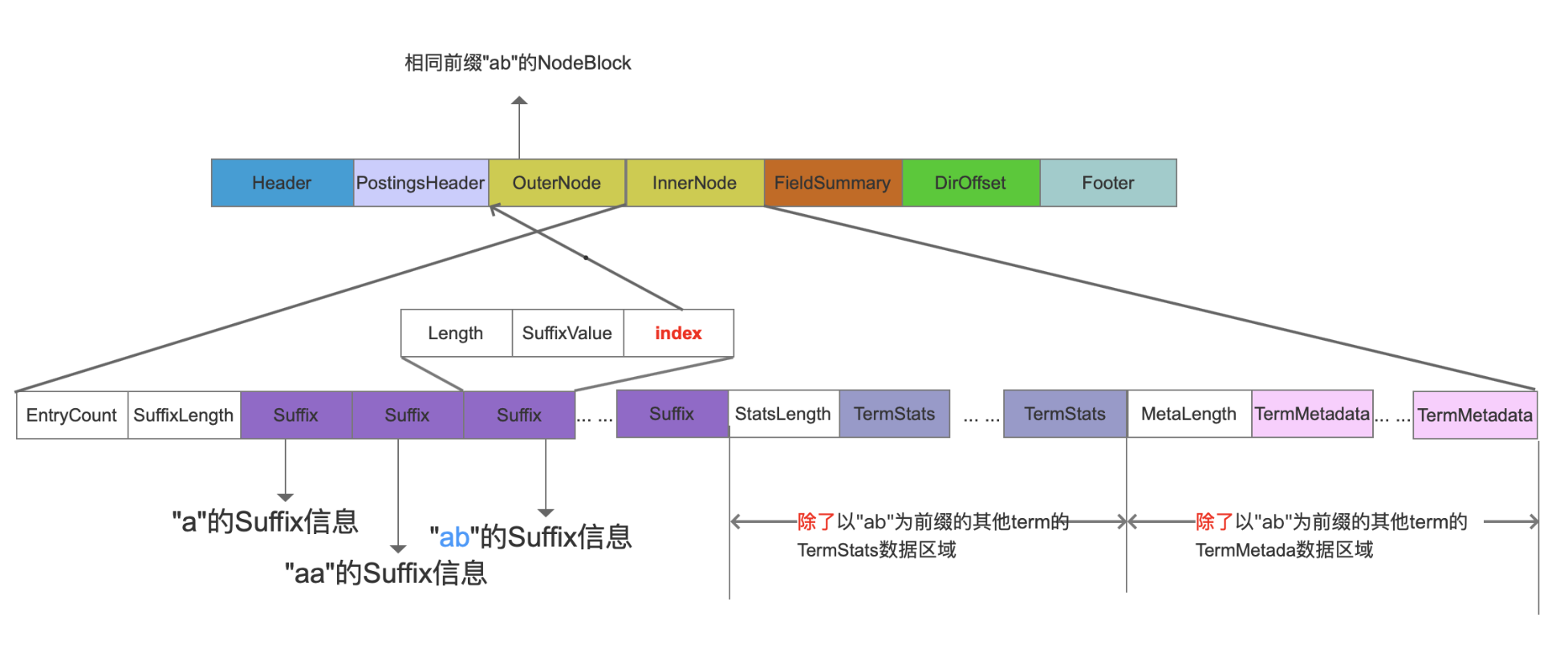 这里TermMate信息中有几个很重要的数据,就是指向前面doc、pos、pay文件的指针。
这里TermMate信息中有几个很重要的数据,就是指向前面doc、pos、pay文件的指针。
**SkipOffset **
SkipOffset用来描述当前term信息在.doc文件中跳表信息的起始位置。
DocStartFP
DocStartFP是当前term信息在.doc文件中的起始位置。
PosStartFP
PosStartFP是当前term信息在.pos文件中的起始位置。
PayStartFP
payStartFP是当前term信息在.pos文件中的起始位置。
- tip文件
接下来就来到了我们今天最重要的文件tip,FST的存储文件。

FSTIndex
FSTIndex记录了NodeBlock在.tim文件中一些信息,比如说fp为NodeBlock在.tim文件中的起始位置,hasTerms描述NodeBlock中是否包含pendingTerm对象, isFloor表示是否为floor block,然后将这些信息用FST算法存储,在前面的博客中有介绍FST的存储过程。
IndexStartFP
IndexStartFP描述了当前的FSTIndex信息在.tip中的起始位置。
DirOffset
DirOffset描述了第一个IndexStartFP在.tip中的位置
3.2 FST源码
FST的构建由负责完成 org.apache.lucene.util.fst.Builder,FST的构建由org.apache.lucene.util.fst.Builder.Node (状态节点)和org.apache.lucene.util.fst.FST.Arc
- Node类 将Node分为两类,CompiledNode和UnCompiledNode。 CompiledNode是已经处理过的Node,就是上一节中冻结了的Arc的Node UnCompiledNode还未处理的Node,对应上一节中还在处理中Node,对应的出弧可能会发生变化
static final class CompiledNode implements Node {
long node;
@Override
public boolean isCompiled() {
return true;
}
}
/** Expert: holds a pending (seen but not yet serialized) Node. */
public static final class UnCompiledNode<T> implements Node {
final Builder<T> owner;
public int numArcs;
public Arc<T>[] arcs;
// TODO: instead of recording isFinal/output on the
// node, maybe we should use -1 arc to mean "end" (like
// we do when reading the FST). Would simplify much
// code here...
public T output;
public boolean isFinal;
public long inputCount;
/** This node's depth, starting from the automaton root. */
public final int depth;
static final class CompiledNode implements Node {
long node;
@Override
public boolean isCompiled() {
return true;
}
}
/** Expert: holds a pending (seen but not yet serialized) Node. */
public static final class UnCompiledNode<T> implements Node {
final Builder<T> owner;
public int numArcs;
public Arc<T>[] arcs;
// TODO: instead of recording isFinal/output on the
// node, maybe we should use -1 arc to mean "end" (like
// we do when reading the FST). Would simplify much
// code here...
public T output;
public boolean isFinal;
public long inputCount;
/** This node's depth, starting from the automaton root. */
public final int depth;
...
}
- Arc
public static class Arc<T> {
public int label; // really an "unsigned" byte
public Node target;
public boolean isFinal;
public T output;
public T nextFinalOutput;
}
-
FST 存储数据 主要代码在:
org.apache.lucene.util.fst.FST.addNode(Builder
, UnCompiledNode )
index或称target 当前arc描述的字符不是输入值的最后一个字符时,会存储一个index值来指向下一个字符的四元组信息中的flag值在current[]数组中的下标值。
output Arc中的输出值,如果output为0,那么就不用存储,在查询阶段,会对一个输入值的所有arc的output值进行整合,合成一个完整的output。
label label值即我们的输入值中的一个字符,Arc的输入值。
flags 由于构建FST后,所有的信息都存在current[ ]数组中,这过程实际是一个编码过程,在构建阶段,需要生成flags,是复合标志位,见源代码
//arc对应的label是某个term的最后一个字符
static final int BIT_FINAL_ARC = 1 << 0;
//arc是Node节点中的最后一个Arc,上文中我们说到一个UnCompiledNode状态的Node可以包含多个arc
static final int BIT_LAST_ARC = 1 << 1;
//上一个由状态UnCompiledNode转为CompiledNode状态的Node是当前arc的target节点, 它实际是用来描述当前的arc中的label不是输入值的最后一个字符
static final int BIT_TARGET_NEXT = 1 << 2;
// arc的target是一个终止节点
static final int BIT_STOP_NODE = 1 << 3;
//arc 是否有输出值
public static final int BIT_ARC_HAS_OUTPUT = 1 << 4;
//acr的目标节点有输出(final output)
static final int BIT_ARC_HAS_FINAL_OUTPUT = 1 << 5;
按照方法进行构建我们在2.2.1中FST对象存储的二进制对象,我们先看一下FST的有向无环图的冻结迅顺序为:
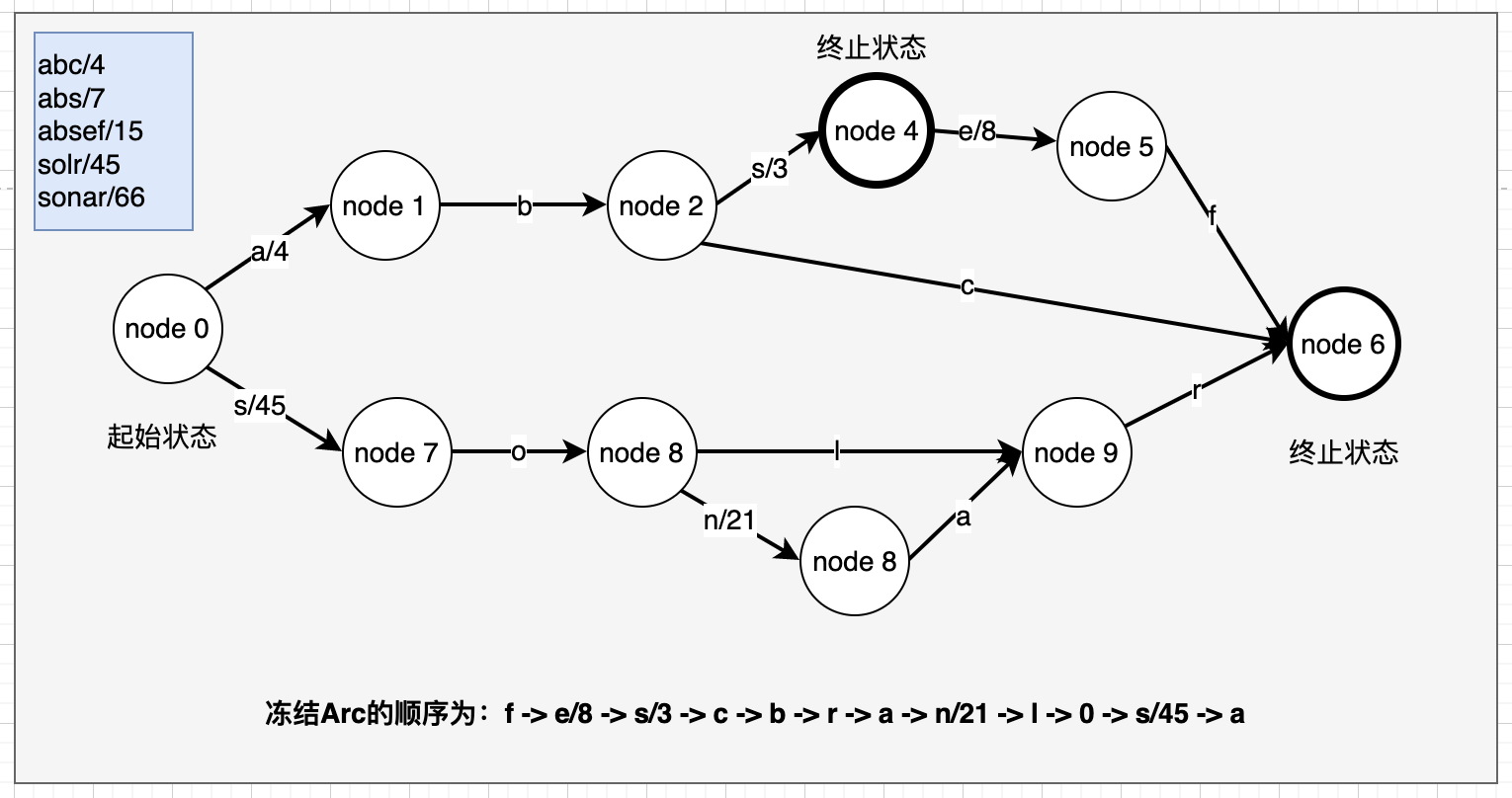
按照冻结的弧和节点的写入值为:
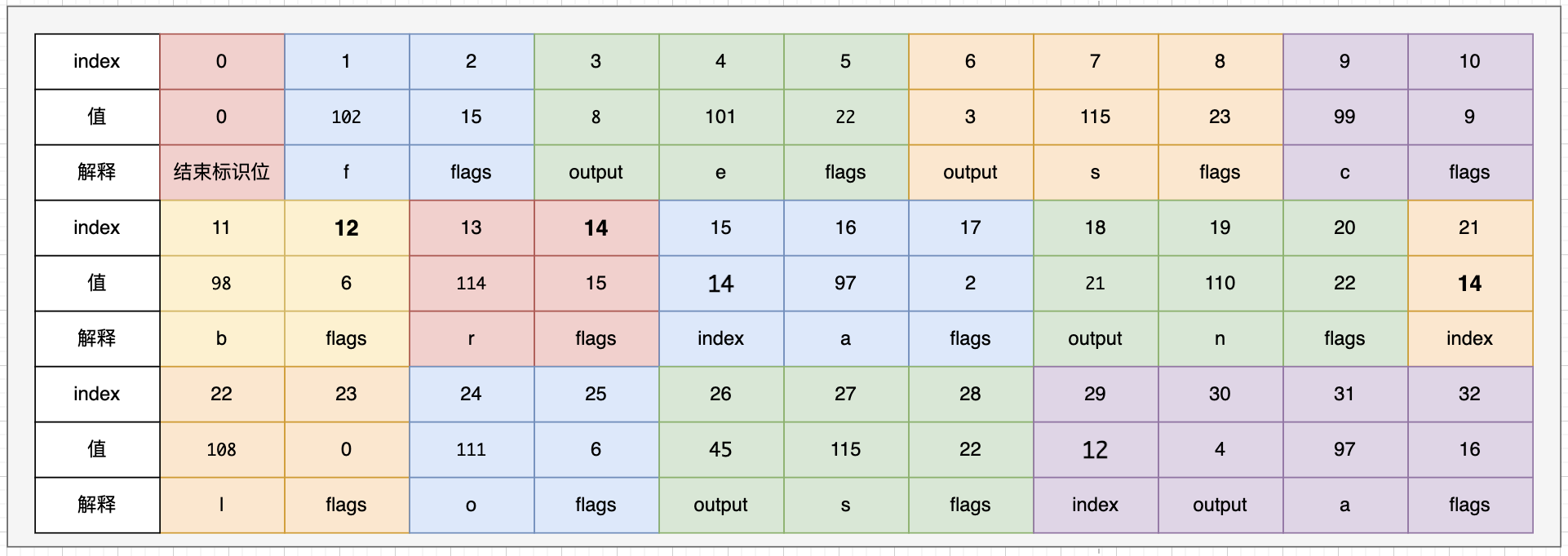
仅使用32个字节将5对字符串KV写入磁盘和内存。
3.3 Demo
测试代码将FST和HashMap作了一个不太严格的测试,确实发现FST比HashMap要慢,本人macbook pro测试,1万次查询,FST 22ms,HashMap 1ms
public class FstTest {
public static void main(String[] args) {
String[] inputValues = {"abc", "abs", "absef", "solr", "sonar"};
long[] outputValues = {4, 7, 15, 45, 66};
try {
PositiveIntOutputs outputs = PositiveIntOutputs.getSingleton();
Builder<Long> builder = new Builder<Long>(FST.INPUT_TYPE.BYTE4, outputs);
IntsRefBuilder intsRefBuilder = new IntsRefBuilder();
for (int i = 0; i < inputValues.length; i++) {
builder.add(Util.toIntsRef(new BytesRef(inputValues[i]), intsRefBuilder), outputValues[i]);
}
FST<Long> fst = builder.finish();
long start = System.currentTimeMillis();
Long value = Util.get(fst, new BytesRef("solr") );
for (int i = 0; i < 10000;i++ ) {
Util.get(fst, new BytesRef("solr") );
}
System.out.println(value + " 耗时:" + (System.currentTimeMillis() - start) ); // 45
} catch (Exception e) {
e.printStackTrace();
}
Map<String, Long> map = new HashMap<>();
for(int i = 0; i < inputValues.length;i++ ) {
map.put(inputValues[i], outputValues[i]);
}
long start = System.currentTimeMillis();
Long value = map.get("solr"); // 45
for (int i = 0; i < 10000;i++ ) {
map.get("solr");
}
System.out.println(value + " 耗时:" + (System.currentTimeMillis() - start) ); // 45
}
}
四 欢迎大家关注我的公众号,探讨交流

参考文档:https://www.amazingkoala.com.cn/Lucene/Index/2020/0110/125.html https://www.amazingkoala.com.cn/Lucene/Index/2020/0103/123.html https://www.amazingkoala.com.cn/Lucene/yasuocunchu/2019/0220/35.html